Lots of articles have been written about the ridiculousness of NFT’s (Non Fungible Tokens) and examples of outrageous amounts being paid to ‘own’ digital items. While I agree that the amount that some people are paying for NFTs are head-scratching, I think there is a place for NFT’s in the future.
Here is a good overview article on NFT’s. I think we are early in this trend, and while it is in the experimental phase I think alot of crazy things will be bought and sold. But conceptually, NFT’s do have advantages over physical collectables. People buy collectibles because they like having the items around them, and they hope that someone else will find them more valuable in the future. The same is true of NFTs. Except with NFT’s, you don’t need to worry about accidental destruction of your collectible, dedicate a room to house all that stuff, or insure it. Some might say they want to physically touch the collectible, but for the most expensive ones, you can’t since that could cause wear and tear and reduce the value. I addition, any NFT that has an official registry can guarantee you have the authentic ownership – where as a physical asset may be a forgery or a copy.
One knock on NFT’s is the lack of scarcity – and how people are just putting all sorts of things up for sale. That is not unique to NFT’s – the amount of physical collectibles out there are seemingly unlimited – from movie franchises, artwork, coins, furniture, just about anything. Anything that someone thinks might be worth more in the future.
So once the hype phase and headlines die down on these NFT’s that are being sold I think someone will find a model that makes for sensible NFT collecting. I think the NBA has an interesting model with it’s top-shot collection. One old school NFT is domain name collecting – people don’t think of that as NFT’s, but what are you really buying when you buy a domain name. Once scarcity in a digital item can be defined, it is a candidate for collecting.
One other interesting model is Earth2.io. This is quite interesting to me – because it has a defined scarcity of elements you can buy (grids on planet earth), and because people seem to be paying a lot of money for these grids. I could spend money on their site to buy the 3 or 4 grids of my house location for around $300 bucks. The reason I would do that is to stake my claim on earth2, and believe that my investment would be worth more in the future. If earth2 can build into something that catches popular culture’s imagination and becomes the most talked about investment since crypto – then that seems like a great investment. But this is just one of many NFT models out there, and so whether it amounts to anything or not will be interesting to watch. As interesting as I find Earth2.. I have no plans to buy land.
I will keep being amused by all the crazy things that people are selling and buying in the NFT world, as it makes for great stories. But long term I do believe there is something to NFT’s as a collectible and a store of value. Maybe even more so than crypto currency, which lacks the collectible aspect of an ‘asset’. I will be keeping my eye out for the NFT that I think has the right model, and maybe then I will join the world of digital collectables.
I finally built a position in Apple stock after years of being out of it. The last time I held Apple was in 2013, but I sold out based on just not being a believer in the company. I was not impressed with their ability to innovate, and I didn’t think their app store margins could hold up, so I thought there were better opportunities elsewhere.
For the most part – I was wrong.
I will admit that it has been hard to match the performance of the S&P 500 without holding any Apple stock. Apple accounts for around 5% of the S&P 500 – so I have been missing an important factor in my quest to beat the S&P.
I am not in the Apple ecosystem – the only Apple product in our house is my spouse’s work phone. But I am seeing a few reasons to buy the stock now – which is what let to my change of heart:
A Bond Proxy. As mentioned in previous posts, holding bonds seems like a no-win situation. I don’t see rates falling much more, so the only thing they can do is stay flat or go up. When rates go up, bond prices fall because old bonds are less attractive than new bonds issued at higher interest rates. So if rates stay flat, Apple’s yield pretty much matches a bond’s interest rate. And if rates go up, I think Apple will be hurt less by higher rates than bonds. Yes Apple is overpriced currently on a historical basis, and it could drop if rates go up, but long term I think its a better bet than bonds. I have a hard time seeing Apple stock being lower in 10 years, than bond rates being lower in 10 years.
Apples New Chipsets. There has been alot of hype around Apples new M-1 chip, which perhaps is overdone, but I think the chip is still a huge improvement over Intel’s offerings. I am in the camp that the the sun setting on Intel’s x86 architecture, and Apple is has made a big step away from that. In addition, with Microsoft looking at Windows for ARM, and servers switching to ARM from x86, I think Apple has taken a lead in the movement, and will draw market share short term in the PC market until (unless) PC’s migrate to an architecture as performant as the M1.
Augmented Reality. As mentioned in a previous post, Apple is moving into Augment Reality and possibly Virtual Reality (AR/VR). I mentioned that I think the lack of progress in AR/VR is a product problem, not a technology problem, and I do think Apple with its strong ecosystem has a decent shot of building something to really be the next generation device. If so, it will power upgrades across all their hardware offerings.
Other new devices. Apple is only strengthening their ecosystem with well designed products. I was skeptical that Apple could build the watch business, but I think I was wrong about that. This week they announced their new Air-tags, which I think are a compelling offering, and they are making real progress with home automation with improvements to Homekit. One problem with home automation is the complexity of setting up devices and all the different apps and ecosystems – and Apple has the ecosystem that is stronger than all the others.
I still am skeptical that Apple can keep their 30% margins in the app store – we have already seen them start to weaken on their pricing. But at this point – I think they have enough new products to build their ecosystem and user base to offset any margin shrinkage. I had also been skeptical that Apple was not much of an innovator – every year they just add silly bells and whistles to their phones to get people to upgrade. But I am seeing enough evidence now that they have been doing a great job innovating all their products into an ecosystem, with a real vision on how it will all fit together.
I hate buying stocks like this after a long huge runup, but I am not looking for this new stock position to ‘knock it out of the park’. Apple will be just a core position that I hold and hopefully just watch it grow slowly, as the company sucks more and more people into their ecosystem. I still have no plans to buy any Apple products.. but never say never.
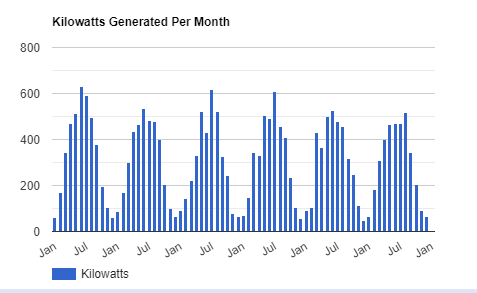
I have just finished compiling my statistics for the 2020 solar year, and overall it was a good year. Production from my panels were down from 3591 kilowatts in 2019 to 3523 in 2020. Below is my monthly production since 2015:
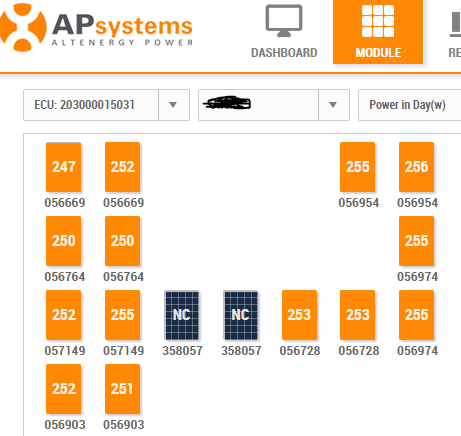
In January, I noticed a couple panels quit producing, and Pacific NW Solar was able to reboot it remotely. In March I had a power inverter go out and it needed to be replaced, which Pacific NW Solar did under warrantee. I highly recommend to anyone installing a solar system to get the wireless reporting module, as that is how I detected the panels werent producing:
One of these days I will write a routine to automate the checking of production by panel, but in the meantime I just go out periodically and verify all is performing normally. Luckily the first outage was in January when production is almost non-existent anyway, and March when I am still not in peak production. Overall maintenance continues to be manageable. I am down to cleaning the panels once a year in spring (before peak production starts), and that seems to be enough to keep them producing at optimum production.
Payback Update
My current estimated payback year for this solar system is now targeted at the end of 2024. In reading thru all the incentive information, it appears 2020 was the last year for incentives for systems installed in 2015. This will take a huge chunk out of my annual revenue. I have a balance of about $1900 bucks to pay off to break even, and without the incentives the revenue my panels produce is estimated to be just over $450 a year. One positive from a production point of view is the marginal rate on electricity has now gone over $0.11 a kilowatt, so that will help the payback. Rates have risen much slower than I projected when I installed the panels, but I do anticipate rates to continue to rise.
Usage Update
In this year of working full time at home, its not surprising that I saw a big increase in usage. Our electrical usage was up 11% for the year after 3 previous years of slowing consumption. The amount of excess solar energy our panels returned to PSE (our electric utility) was also way down, indicating much more use during the day during peak production hours. Given that this work from home thing may be a permanent way of life, I don’t anticipate usage going back down to previous levels anytime soon.
I have no changes planned for my configuration, I just hope things keep humming along. As always, if you are considering an installation and have any questions for a solar system owner, feel free to leave a comment.
I have been building prediction modeling applications for years as a investor, as a way to try to identify when the various asset classes or particular stocks may be over or under priced. My current model is over 15 years old, and as you might guess is becoming a huge mess of code-spaghetti which is becoming difficult to modify.
Recently, I stumbled across a full suite of college football data, and started to wonder if one could build a model to predict college football games. Rather than try to copy my existing investment model, I decided to mentally start from scratch and figure out the best way to design predictive models for maintainability. I now have a college football game prediction model up and running, using my new pattern I designed during this process:
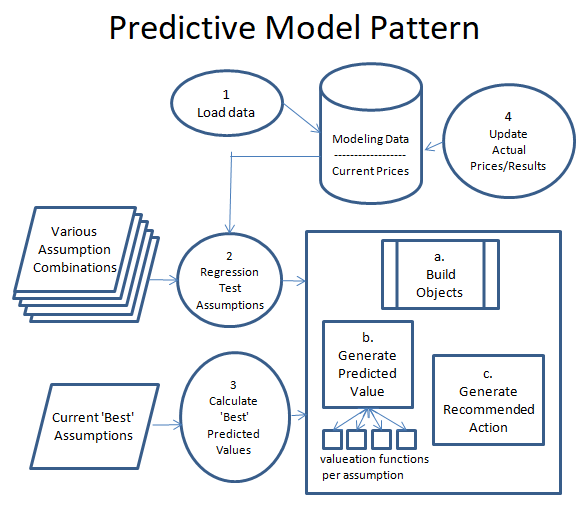
Now this might be Data Science 101 to a data scientist, but this is not my area of expertise. My software suite is a SQL Server database and C#, tools I am very comfortable with. Rather than learn new tools and software specially built for data modeling, I thought it would be more interesting to design my own custom approach. I am a software developer, so my thinking how how to build this process was inspired my Model/View/Controller (MVC), a software design pattern that focuses on separation of logic for interconnected systems. So taking this foundation, I have broken the process of setting up an managing the model into 4 main components.
Create Program to Load Data. Before I build a model, I have to make sure I have access to the data necessary to power it. There are plenty of great API’s to gather investment data, and if necessary data can be gathered via data scraping. I have a good library of tools to call APIs, and a nice suite of data scraping tools. So building the logic usually takes some time, but the logic to gather the data can be nicely compartmentalized for easy maintenance.
Create Program to Regression Test Various Assumptions. Before building the program, you have to define a rough set of assumptions as to the cause and effects of various factors. The set of assumptions you create can only be limited by the data you have available. For example, for my College Football prediction model one assumption I tested was that a team is more valuable after a big home game loss. The assumption is the team might be more motivated to do well following a bad home loss, and potential betters are soured on the team. So you look at the data you have, then create various assumptions you can test against the data. Once you have a set of assumptions, you create a program to fire the assumptions at your prediction engine with varying the weight of each assumption each run. Doing this you hopefully identify assumptions that have no correlation to future performance, and ones that have a strong correlation or inverse correlation to future performance. Below I have expanded on how the prediction engine is built, as it is a core piece of the program.
Create Program to calculate the ‘best’ predictions. Once you have tested various factors against your historical data, choose the factors and weightings of each factor that performed best of all the factor combinations you fired at at the prediction engine. This will be what generates the predictions, then looks at the current price (or the current betting line in the case of my college football model), and determine the ‘best’ value prediction. Note that I plan to rerun my regression tests on this model quarterly, so that I can see how well the assumption weightings are holding up. If some start to deteriorate, I may adjust factors and weightings as appropriate.
Create Program to track predictions and update results. I think this is perhaps the most important piece. The prediction engine bases it’s prediction based on past data, so it is important to see if past data accurately predicts future results. So for example for the college football predictions, every Monday I run a job that updates the weekend scores, then compares the results to my predictions for the week. Each week I will look closer at the losses, to see what I missed, and maybe give me some ideas for additional factors to add. Of course, new factors may mean collecting more data, which further adds to the effort of building and maintaining the model. It is a very iterative process, as optimizations can always be made.
The Prediction Engine
Building the prediction engine is an iterative process in itself. The plan is to start small, then slowly add additional calculations over time. As long as additions are managed in an organized manner, the code base should be maintainable even after adding a large number of factors. The prediction engine (described in the big square in the diagram above) consists of 3 major parts.
a. Build Objects. The first thing to do when firing up the prediction engine is to pull the data stored in the database into a view model that exposes the data in a way to be easily accessible. These are typically complex objects that represent the entity you are making a prediction on (i.e. football game, a stock market security, asset class, etc.). For instance, a college football model would pull in a game object, which would have two teams attached to it with all the statistics and history needed for each team. For instance, a ‘bad previous week home team loss factor’ will require looking at past game performance in order to see if the a team had a bad loss in the previous week. As long as the data is there, that is a fairly simple subroutine to write.
b. Generate Predicted Value. Now that you have your data accessible – fire your list of assumption factors and weightings to calculate a value. To simplify the architecture of this, I have a separate subroutine for each factor calculation to try to avoid my logic bloat. This will allow me to isolate factors, and add new ones or delete invalid ones as necessary.
c. Generate Recommended action. Once you have calculated the value of all your assumptions against an object, you should have a score for that object. That score can then be compared to the price of the object to see if there is any action to be taken. For example, take a college football game, and given your assumptions and the data available step b came up with a calculation that the home team should win by 3 points. If the betting line has the home team favored by 14, and your threshold for action is a 7 point differential, then the recommendation action would be to place a bet on the visiting team. The same works for a stock market security. If step b calculates a stock price of $15, and the stock is priced at $10 the recommended action might be to buy the stock.
Note that it is also valuable to track the variability of the model in the form of standard deviation or R value. Some models may show a coorelation, but have a wide deviation. These deviations will help you set your ‘time to take action’ price. Typically the wider the deviation, the higher I set my action price.
Breaking the logic for this prediction engine into segmented parts should really help the management of the logic. In addition, I have a pretty good library of reusable logic components that I should be able to apply across multiple predictive models. My goal here is to slowly increase the size and scope of the calculations, while keeping the overall system pretty simple.
Now that I have my college football predictive model working, I will just continue to add assumptions to see if I can continue to increase the accuracy of my predictions. Then I will start tearing out components of my existing investment prediction engine, and rebuild it using this new model.
When will I be done with this project? Hopefully never. If all goes well, these models should be continually evolving and growing as more data is collected, and hopefully become more accurate.
Recently I got a comment on my first Blazor and WordPress blog post that my demo wasn’t working. I hadn’t looked at it in months, but sure enough my weather forecast component wasn’t rendering. Blazor was working, but it was defaulting to ‘route not found’ condition.
I have learned a bit more since my original experiment, so I dug back into my demo and made some improvements.
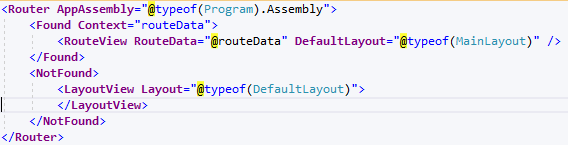
In my first version, I used the router, and set my @page directive to match the url of the blog post.
For some reason the router was no longer recognizing that route. I assume some wordpress upgrade messed with the url rewriter, but I didn’t look into that closely – I decided that was the wrong approach. Instead, I just updated the router (my app.razor file) to rely on the notfound condition:
Now my app has no routes defined, and I rely on my defaultlayout.razor page to always render. Note that I can likely get rid of the <Found condition in the router – I didnt only because it was working and I didn’t want to mess with it anymore.
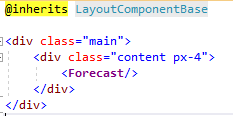
So my DefaultLayout.Razor file is pretty simple:
All it essentially does is render my weather forecast component. I think this is a much better pattern to use when embedding Blazor in WordPress. If you do need to deal with routing, my recommendation would be to either sniff the url in your blazor app and decide what to do, or just control the state of your components by setting variables that cause components to either show or hide.
A couple other thoughts:
You may have to add mime types to your WordPress server if your app doesn’t work or you get console errors. Take a look at the web.config that gets generated when you publish, and you will see the ones you need. If you manage the wordpress hosting server you can add them in on your admin panel. If not, there are some wordpress plugins that allow you to manage mimetypes.
I am beginning to wonder if embedding blazor in wordpress is the right architecture. The other option is build a blazor app that calls the wordpress API – and just have it pull all the wordpress content into your standalone blazor app. That way you can still maintain the content in wordpress, but you have the full flexibility of blazor routing. If you don’t change your themes a lot, and you don’t require a lot of plugins, this approach might be better. Just a thought. SEO would be an issue in this approach though, since search engines don’t appear to index Blazor apps.
For reference, below is the working example of the Blazor rendered weather forecast:
Loading…
I am surprised there is not more chatter on the internet about integrating WordPress and Blazor – its a pretty interesting solution to quickly adding components to a WordPress site. If you follow the instructions from my previous post, along with the things I learned above, you can easily get it set up.
I have been building out my first Blazor application, and have been figuring out the pattern I want to follow for user authentication. Rather than use the built in Blazor authentication components, I am using the libraries I have built over the years, and I can plug into almost any app without having to think.
Where I got tripped up a bit with Blazor was in communicating the logged in an logged out status across components. After lots of Googling and experimenting, here is what I came up with:
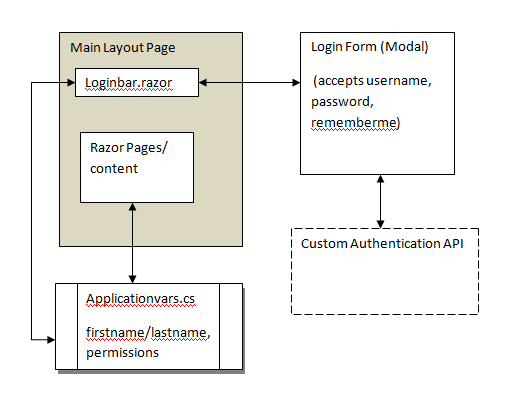
In my Blazor Mainlayout page, I embedded the login bar component directly. This login bar just shows a login button, or if the user is logged in shows a logout button and the users name. When the signin button is clicked, the logon bar launches a login form component to collect username and password, and call the authentication API with the credentials. When a login is successful, the login bar updates a singleton class applicationvars.cs that holds all the profile information. This singleton allows all pages in the application to access these values. This is a nice, compact, and elegant way to handle what we used to call global and session variables – and is rapidly becoming one of my favorite things about Blazor.
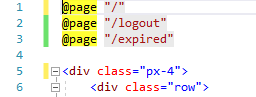
Where I got tripped up was when I wanted to enforce a logout, or deal with a user session expired situation and message it appropriately. I finally settled on the solution of adding multiple routes to the same index page. I built route called ‘/logout’ and ‘/expired’, and added that route to the index page:
Where I erred was I put the logic to destroy the credentials in applicationvars inside the index page, which renders after the login bar, so the login bar didn’t reflect the credentials change. I futzed around with trying to get the index page to fire an event when the logout is detected, and have the login bar listen for the event and update appropriately. The better solution was to have the loginbar sniff the url, and when it sees the logout or expired URL, it destroys the credentials and redirects to the appropriate index URL. It was a much more elegant solution than getting the event wired up. It makes me wonder – maybe a new rule I need to follow: for your average business application, if you have to fire an event, you are probably doing something wrong in your design.
This design is working, and so far it has nicely isolated the authentication logic from the rest of the application. One worry is there is no easy way to have the app communicate with the login bar, so I may have isolated it too much. In recent various Blazor blog posts, I have noticed people are moving away from the singleton approach in favor of wrapping application vars around the whole application in the router. This new technique doesn’t change the over concept, so I may adapt that pattern in my next project. But for now, I will proceed with this pattern, and see how many times this paints me into a corner I don’t want to be in.
I have been reading a lot of bad reviews about Microsoft’s new dual screen device called the Surface Duo. What I find most surprising is most the bad reviews center around the lack of purpose for a dual screen device. The Windows Blog provides a pretty good overview of the device.
Surface Duo
It seems to me there would be demand for a dual screen device – no so much for single app use, but for business multitasking. It seems to me the logical use case is to have one side of the phone for apps consuming media, the other side for apps where your create media. So if I was to get one, I would likely keep my email and messaging app on one side, and my web browser and reading apps on the other. Other use cases Microsoft shows that essentially using the device as a doublewide screen are less compelling to me, as even a double wide screen is probably too small to do any real work. But for a productivity tool, I think this form factor will catch on.
Besides the consternation regarding how to use the device, the bad reviews have focused around the low specs on this device. On this point I agree – for a list price of $1,400, I would want a more high end device.
The low end specifications for such a high priced device will put this product at a disadvantage, and it may not succeed. But I don’t necessarily think Microsoft was planning on a huge success in this round. This is an experiment and I think they are looking to see what users and app developers do with this form factor. Again, at $1400 this device isn’t for me, but I give Microsoft credit for putting it out there.
In the past few months I have become more curious about the air quality of our house. I noticed as I get older I feel more congested in the winter, and lately our cat has been sneezing more – so I decided to throw technology at the question. In the winter here in the Pacific Northwest, we keep the windows closed most days in winters, and we don’t usually have all the rooms in our house fully heated. In winter months, when I am not heating my office it can dip down to the low 60’s, and with the wet weather we receive, I wonder if we have mildew or other organisms that like damp, cool environments.
So I decided to research air quality trackers, and came across this Awair Air Quality monitor.
APPIP ERROR: amazonproducts[
TooManyRequests|The request was denied due to request throttling. Please verify the number of requests made per second to the Amazon Product Advertising API.
]
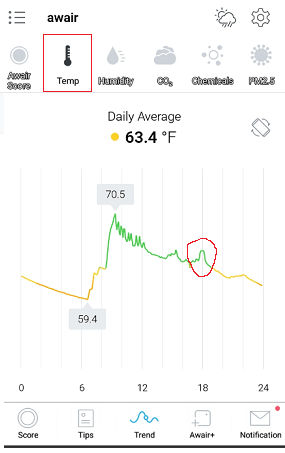
I was able to buy it at just over $100, and while it was more than I wanted to spend, but I couldn’t pass up the connected home features this one offers. It comes with a nice app that gives you more than enough information about your home air quality. I set it up in my office where it sits on my desk and I can see the numbers go up and down. I have it set up to give me notifications on my phone when thresholds exceed certain levels. After watching it for several months, the only thing it gives me a low score is typically on is the temperature and humidity. If I don’t have the heat on in my office, the humidity can quickly rise to above 70% on rainy days, which isn’t great. So I have been using this monitor to manage the humidity without grossly heating an empty room.
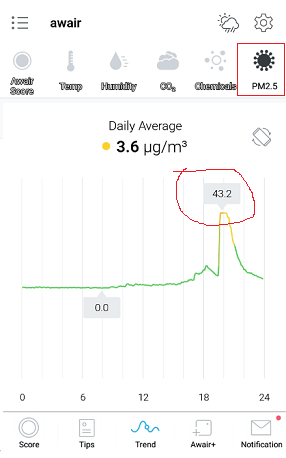
This does detect chemicals in the air pretty well though. One weekend, I got an alert from my Awair that chemicals in the air were high. I was just sitting in my office, and the numbers were spiking out of nowhere. After thinking about all the stuff I had been doing that day, I realized what was probably causing the issue. Earlier in the day around 2pm, I had painted a closet door in the garage with latex paint, and after I was done I used a utility sink to wash out the brush I was using. I have done this for years, never thinking anything of it. Well it turns out, the furnace is in the same room as the sink, and when the heat kicked on, it must have picked up all the latex compounds that I washed in the sink.
Note that from the above data the number spike corresponds to a heat increase around 4:30pm – when the furnace kicked on. Amazingly just washing paintbrushes was enough to hit an unhealthy level in the house. Since then, the numbers have gone back down to normal and have not spiked since. I have some more painting to do – so I will test this out again just to prove my theory.
I tried moving the Awair to the Kitchen, and it seems pretty accurate detecting smoke from cooking too. Pretty much anytime when cooking, the particulate numbers will elevate, and turning on the kitchen fan does affect the numbers. Interesting the quickest way to get the numbers down is to open doors and windows, which almost immediately flushes the air.
For just over $100, this Awair appliance is interesting, although once you measure your air for a period of time, it doesn’t give you much actionable info. And I am not sure it answers my question about the mildew or mold in the air, but it does tell me I have no major problems. For now though, my indoor air quality is for the most part excellent and so I can rest (and breath) easy.
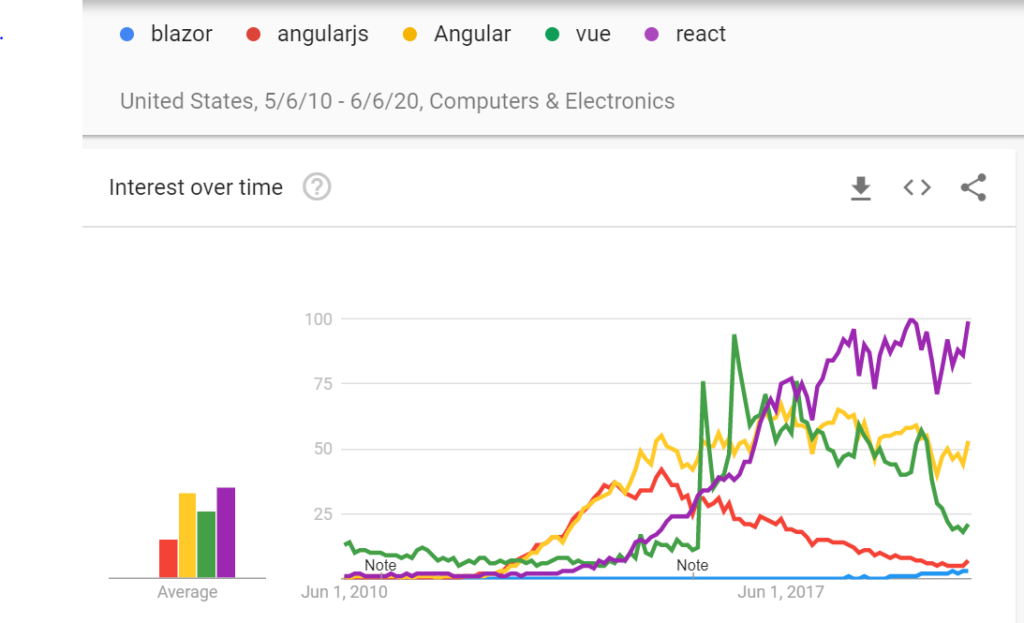
If historians ever write about software development in the 2010’s, the main discussion point will have to be the mess caused by JavaScript and competing JavaScript frameworks. The chart from Google trends shows how each year a different JavaScript framework was the ‘best framework to use’:
The reason this happened is they are all inferior. A JavaScript framework itself is a tool to try to cover up the deficiencies of JavaScript, a language that had developers grasping for a tool that would help. With frameworks came helper packages to help deploy frameworks, leading to a huge conglomeration of various packages needed to write front end software to run in a web browser.
The legacy of this mess will be with us for years. React is currently the winning framework (if you use Google search trends as a guide), and so new applications will more likely be written in React than the other frameworks. Thus, the pool of experienced developers with these older frameworks will shrink, making it more difficult to maintain these applications written just a few years ago. And no developer will want to put Vue or AngularJS on their resume when React is what is in demand at the moment, further weakening support for the older frameworks.
Granted many developers who know one framework know others, but the pressure will be one to translate, or rewrite an application from one framework to another. And that effort is expensive. Given that the business rules have likely changed since the original app was written in the mid 2010’s – it’s likely a new app in the current framework will be written from scratch. The good news I guess is since these apps only had a useful life of say 5 years, they will be easier to rewrite – but it won’t make the business person paying the bill feel any better.
Here is where I bring up Blazor – my favorite development tool of the day. While everybody is still writing apps using React – I think Blazor will be the ultimate winner. Its a much simpler, elegant, and efficient front end than any JavaScript framework can build. Remember – JavaScript frameworks are built on JavaScript, an un-typed, interpreted language. Blazor is a binary in WebAssembly using C#, allowing full stack developers to work in the same language from the front end to the server.
It’s still early days for Blazor, as the chart above shows. But I am confident that Blazor will be the winner, and I am currently writing all new apps using Blazor. Unfortunately for the business world, I expect in a few years I will be fielding lots of requests to rewrite very young React applications in Blazor.
I dont follow Apple all that closely, but I was interested to see that they are moving into the Augment / Virtual reality (A/R V/R) space with an upcoming product. This article shows schematics for upcoming A/R glasses which makes sense for Apple. From the article:
Apple is rumored to have a secret research unit comprising hundreds of employees working on AR and VR, exploring ways the emerging technologies could be used in future Apple products. VR/AR hiring has ramped up and Apple has acquired multiple AR/VR companies as it furthers its work in the AR/VR space.
This makes sense, as this would be the next logical extension to the Apple Watch. It looks like they are headed in two directions – Apple Glass which would provide an easy way to get notifications – kind of a heads up display for everyday use.
According to the rumors Apple appears to be working on a V/R headset also. This has been rumored for some time, but there are more specifics to the rumors:
Along with augmented reality smart glasses of some kind, rumors have suggested that Apple is working on an incredibly powerful AR/VR headset that’s not quite like anything else on the market. It is said to feature an 8K display for each eye that would be untethered from either a computer or a smartphone, and it would work with both virtual and augmented reality applications:
Along with augmented reality smart glasses of some kind, rumors have suggested that Apple is working on an incredibly powerful AR/VR headset that’s not quite like anything else on the market. It is said to feature an 8K display for each eye that would be untethered from either a computer or a smartphone, and it would work with both virtual and augmented reality applications.Rather than relying on a connection to a smartphone or a computer, the headset would connect to a “dedicated box” using a high-speed short-range wireless technology called 60GHz WiGig. The box would be powered by a custom 5-nanometer Apple processor that’s “more powerful than anything currently available.” At the current time, the box apparently resembles a PC tower, but it “won’t be an actual Mac computer.”
For years I have been skeptical of Apples ability to innovate – every year all they innovate is a bigger iPhone or bigger iPad at a bigger price. However, I have to give them credit for getting the Apple Watch to gain market share. Now the real innovation that I am intrigued by is their recent purchase of a company called NextVR. This company ” specializes in recording live events like concerts and sports matches to be experienced in VR “. So Apple might be just the consumer company to finally bring VR to the masses, if they can take the worlds media consumption to a whole new level from streaming TV shows to streaming VR shows.
So keep your eye on Apple – while these are only rumors, it seems a logical next step for the company.