After over 10 years and 337 posts, I have decided to end contributing to my blog. I feel kind of sad about doing it, but I am having a hard time coming up with new topics I feel energized to write about. Perhaps I have said all I have needed to say, and there are a lot more people and platforms where people are writing, so its harder to contribute anything new to the conversation.
My journalistic endeavors won’t end completely. I still plan to write occasionally for Seeking alpha where you can follow me. If I do see something that I have to opine about, I will likely use twitter – mostly for retweets of interesting articles. But that will likely be few and far between.
In previous posts I have written about Blazor – and perhaps that is part of the culprit as to why my posts have dwindled. I am really enjoying programming using that framework – its relaxing like doing a crossword puzzle, and I find a lot of my creative energy going there. This last 10 years has taught me something – programming comes easier to me than writing. I recall a note I saw from my Grandfather who did some writing – who said something like the hardest part of writing is to put your rear end in a chair and start writing. It does take a surprising amount of motivation and energy to coalesce your thoughts and try to put them in a good (or in my case adequate) structure. I don’t seem to have that problem with programming – I can just sit down and open up a program – and the fingers just start flying.
I also plan to continue to work to try to streamline the generation of content. The articles I write for Seeking Alpha take a surprising amount of time and effort to write, and I am still trying to build out a framework for generating articles on a consistent basis. I still have hopes I can do this, after several years of trying. I also want to work more on automating content – perhaps the perfect marriage of programming and content. A simple example of this is what I do on the VFS Daily home page, which generates contest based on various events. One post I don’t think I ever got around to was the rise of computer generate news articles, which you see a lot of in financial and sports reporting. I think at some level I can create something to make it easier to create content – perhaps achieving a goal of Virtual Dan writing articles instead of the real Dan.
But for now, thanks for reading – and we will see if I can devise a future incarnation of Virtual Dan in the future.
Lots of articles have been written about the ridiculousness of NFT’s (Non Fungible Tokens) and examples of outrageous amounts being paid to ‘own’ digital items. While I agree that the amount that some people are paying for NFTs are head-scratching, I think there is a place for NFT’s in the future.
Here is a good overview article on NFT’s. I think we are early in this trend, and while it is in the experimental phase I think alot of crazy things will be bought and sold. But conceptually, NFT’s do have advantages over physical collectables. People buy collectibles because they like having the items around them, and they hope that someone else will find them more valuable in the future. The same is true of NFTs. Except with NFT’s, you don’t need to worry about accidental destruction of your collectible, dedicate a room to house all that stuff, or insure it. Some might say they want to physically touch the collectible, but for the most expensive ones, you can’t since that could cause wear and tear and reduce the value. I addition, any NFT that has an official registry can guarantee you have the authentic ownership – where as a physical asset may be a forgery or a copy.
One knock on NFT’s is the lack of scarcity – and how people are just putting all sorts of things up for sale. That is not unique to NFT’s – the amount of physical collectibles out there are seemingly unlimited – from movie franchises, artwork, coins, furniture, just about anything. Anything that someone thinks might be worth more in the future.
So once the hype phase and headlines die down on these NFT’s that are being sold I think someone will find a model that makes for sensible NFT collecting. I think the NBA has an interesting model with it’s top-shot collection. One old school NFT is domain name collecting – people don’t think of that as NFT’s, but what are you really buying when you buy a domain name. Once scarcity in a digital item can be defined, it is a candidate for collecting.
One other interesting model is Earth2.io. This is quite interesting to me – because it has a defined scarcity of elements you can buy (grids on planet earth), and because people seem to be paying a lot of money for these grids. I could spend money on their site to buy the 3 or 4 grids of my house location for around $300 bucks. The reason I would do that is to stake my claim on earth2, and believe that my investment would be worth more in the future. If earth2 can build into something that catches popular culture’s imagination and becomes the most talked about investment since crypto – then that seems like a great investment. But this is just one of many NFT models out there, and so whether it amounts to anything or not will be interesting to watch. As interesting as I find Earth2.. I have no plans to buy land.
I will keep being amused by all the crazy things that people are selling and buying in the NFT world, as it makes for great stories. But long term I do believe there is something to NFT’s as a collectible and a store of value. Maybe even more so than crypto currency, which lacks the collectible aspect of an ‘asset’. I will be keeping my eye out for the NFT that I think has the right model, and maybe then I will join the world of digital collectables.
I finally built a position in Apple stock after years of being out of it. The last time I held Apple was in 2013, but I sold out based on just not being a believer in the company. I was not impressed with their ability to innovate, and I didn’t think their app store margins could hold up, so I thought there were better opportunities elsewhere.
For the most part – I was wrong.
I will admit that it has been hard to match the performance of the S&P 500 without holding any Apple stock. Apple accounts for around 5% of the S&P 500 – so I have been missing an important factor in my quest to beat the S&P.
I am not in the Apple ecosystem – the only Apple product in our house is my spouse’s work phone. But I am seeing a few reasons to buy the stock now – which is what let to my change of heart:
A Bond Proxy. As mentioned in previous posts, holding bonds seems like a no-win situation. I don’t see rates falling much more, so the only thing they can do is stay flat or go up. When rates go up, bond prices fall because old bonds are less attractive than new bonds issued at higher interest rates. So if rates stay flat, Apple’s yield pretty much matches a bond’s interest rate. And if rates go up, I think Apple will be hurt less by higher rates than bonds. Yes Apple is overpriced currently on a historical basis, and it could drop if rates go up, but long term I think its a better bet than bonds. I have a hard time seeing Apple stock being lower in 10 years, than bond rates being lower in 10 years.
Apples New Chipsets. There has been alot of hype around Apples new M-1 chip, which perhaps is overdone, but I think the chip is still a huge improvement over Intel’s offerings. I am in the camp that the the sun setting on Intel’s x86 architecture, and Apple is has made a big step away from that. In addition, with Microsoft looking at Windows for ARM, and servers switching to ARM from x86, I think Apple has taken a lead in the movement, and will draw market share short term in the PC market until (unless) PC’s migrate to an architecture as performant as the M1.
Augmented Reality. As mentioned in a previous post, Apple is moving into Augment Reality and possibly Virtual Reality (AR/VR). I mentioned that I think the lack of progress in AR/VR is a product problem, not a technology problem, and I do think Apple with its strong ecosystem has a decent shot of building something to really be the next generation device. If so, it will power upgrades across all their hardware offerings.
Other new devices. Apple is only strengthening their ecosystem with well designed products. I was skeptical that Apple could build the watch business, but I think I was wrong about that. This week they announced their new Air-tags, which I think are a compelling offering, and they are making real progress with home automation with improvements to Homekit. One problem with home automation is the complexity of setting up devices and all the different apps and ecosystems – and Apple has the ecosystem that is stronger than all the others.
I still am skeptical that Apple can keep their 30% margins in the app store – we have already seen them start to weaken on their pricing. But at this point – I think they have enough new products to build their ecosystem and user base to offset any margin shrinkage. I had also been skeptical that Apple was not much of an innovator – every year they just add silly bells and whistles to their phones to get people to upgrade. But I am seeing enough evidence now that they have been doing a great job innovating all their products into an ecosystem, with a real vision on how it will all fit together.
I hate buying stocks like this after a long huge runup, but I am not looking for this new stock position to ‘knock it out of the park’. Apple will be just a core position that I hold and hopefully just watch it grow slowly, as the company sucks more and more people into their ecosystem. I still have no plans to buy any Apple products.. but never say never.
I finally broke down and bought some crypto currency. While I was never in the camp that crypto was a fad, I was never a believer enough to actually buy any. What finally tipped the scale for me was seeing all this big money going into bitcoin. More and more big Wall Street money managers are hedging using crypto, and soon you will see ETF’s available which will make it much more easy to buy and liquid. So finally, I bought a tiny enough so at least I can get a better feel for where crypto fits in my investment portfolio.
First I had to decide on a crypto coin. I finally decided to buy Ethereum – not Bitcoin.
I bought Ethereum not because I know what I am doing, I just weighed a few factors:
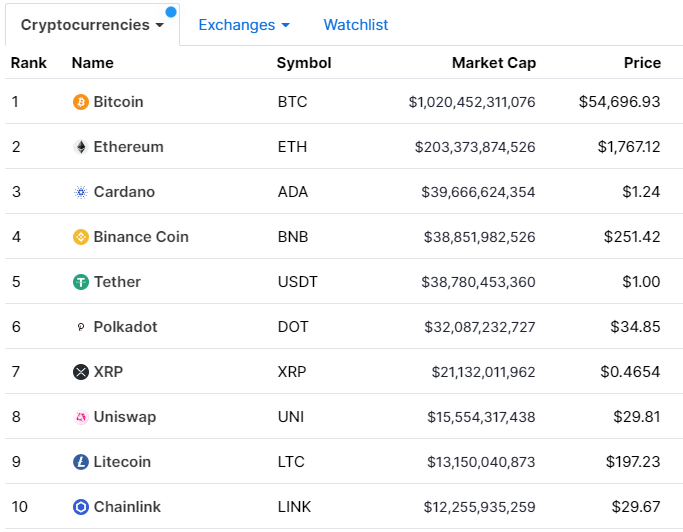
First, I wanted a coin with one of the top market caps. There are a zillion different crypto currencies, and the only ones that are valuable are the ones that people think are valuable. The bigger a market cap gets, the more it represents trust. Here is a chart of the top 10 cryptos ranked by Market Cap:
Second, I noticed that non-fungible tokens (NFT)’s primarily trade in Ethereum. Now that NFT’s are here – crypto currencies are starting to look pretty mainstream. I am not a believer in NFT’s enough to consider buying any, but I do think its an interesting concept – more on that in a future post.
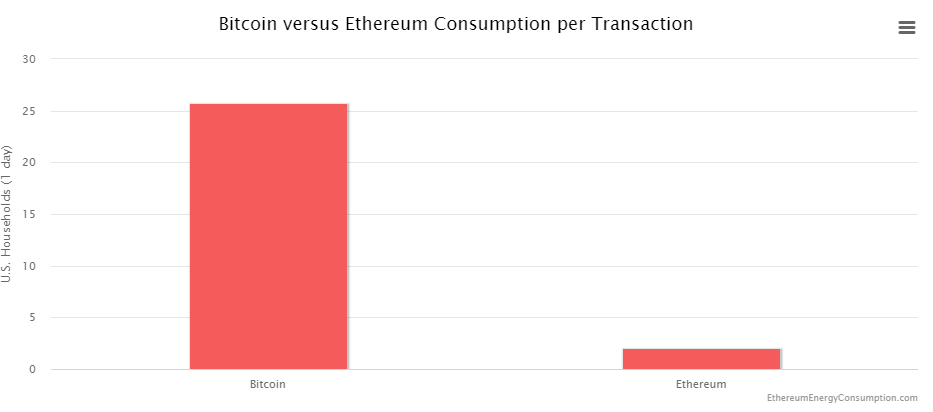
Bitcoin gets a bad rap because of the energy it takes to process transactions, and indeed it is much more energy heavy:
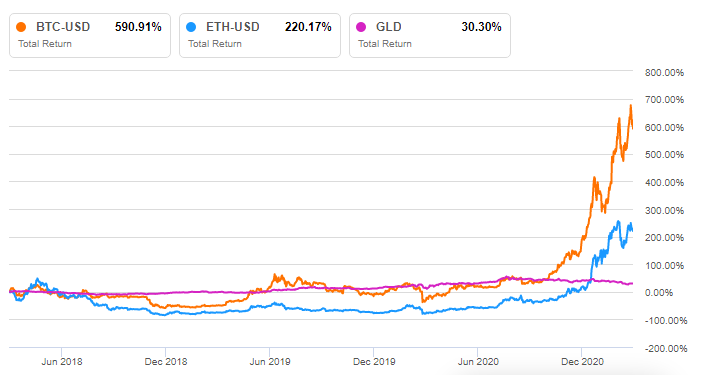
I assume if Ethereum reaches the scale of bitcoin the energy usage will rise to match, but Ethereum does have on its technology roadmap a plan to make it much more energy efficient. While Ethereum has not performed as well as Bitcoin as seen by the chart above, it tracks it close enough for me until I have a better idea of what my strategy is.
Note also from the chart above how both Bitcoin and Ethereum have performed as compared with Gold (GLD). One would think Gold would somewhat match the chart of crypto, but it really hasn’t. I have a small amount of gold stocks I own as a hedge on the stock market. I can foresee wanting to use Crypto as a hedge on my gold hedge. I can easily see the rise of crypto and NFT’s as negatively hurting the price of gold. While crypto and NFT’s have no intrinsic value – gold is only a physical representation of an asset that has little intrinsic value. Its a complicated world.
As far as how I bought my Ethereum, I decided to go the easy way and buy it through PayPal – it was a very simple transaction. Crypto purists would say you really want to have your own wallet and store it off the grid, but I have such a tiny amount its not worth the hassle at this point. I guess if the apocalypse comes and we are bartering crypto currency, I may regret that decision.
For now, I am pretty much in watch and learn mode. This is a crazy investing world of late, and the inflow of the younger generations into investing is really challenging some long time strategies. Crypto may just be a bubble investment, or it might be the start of something big. Only time will tell.
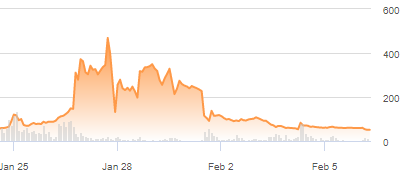
Lots has been written about the recent eruption of Gamestop stock as part of the Reddit rally against the big money on Wall Street, but I thought I would do a quick post just to sum up my thoughts. As you may recall, Gamestock stock went up 1000% after a Reddit Wall Street bets board focused small retail investors to buy Gamestop because it was shorted 140%.
Gamestop Stock Price
I think the initial strategy was correct – I think the fact that GME was shorted 140% was a mistake by the big money algorithm that failed to take that into account. When the reddit member who spotted that and spurred others via the forum to buy the stock was a creative way to profit off that mistake. I think those that got in on the first few days of the price move did pretty well. However, I think most the money that was made after January 26th was made by the big money hedge funds that the reddit movement was looking to punish.
A lot of the sentiment by the retail buyers was driven by hatred of the big money on wall street, and the feeling that the market is rigged against the small investor. To that point, I think it was a success. I think this exposed some tricks the big money used to kill the movement. While maybe Robinhood (the retail broker at the center of this) did have some fiscal reason to prevent traders on its platform from buying Gamestop stock during the heights of this movement, I find it hard to believe the big money behind Robinhood did not put pressure on the broker to keep retail investors from squeezing the shorts. This also brought to light the trade ‘front-running’ which pays for the ‘no-commission’ trades. When you trade a stock on a no-commission basis, it is clear the money is made up by the clearing house not giving you the best price. I also believe the expansion of the Gamestop trade to target other shorted stocks and silver was a deliberate diversion from the Gamestop movement.
The biggest fault I have with this is that it was driven by emotion. This anger at the big money should not of let investors to ignore basic stock fundamentals. One of the earliest lessons I learned (and keep trying not to repeat) is ‘don’t fall in love with a stock’. The mantra of ‘hold at all costs’ on Reddit is a failed strategy. This emotion is what let to all the small investors who joined the movement late to give their money to the hedge funds who know more about price fundamentals. While I don’t disagree with the sentiment on Reddit, I don’t think having thousands of small investors lose money on an irrational trade is the best response.
So that’s my take. I am heartened to see the younger generations take up these activist positions, and perhaps some good ideas came of this event. And I hope these small investors learned a little about mixing emotions with investing, and how important it is in most cases to keep them separated.
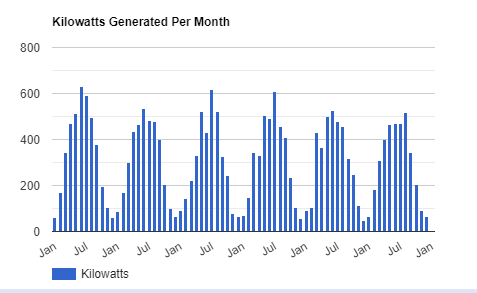
I have just finished compiling my statistics for the 2020 solar year, and overall it was a good year. Production from my panels were down from 3591 kilowatts in 2019 to 3523 in 2020. Below is my monthly production since 2015:
In January, I noticed a couple panels quit producing, and Pacific NW Solar was able to reboot it remotely. In March I had a power inverter go out and it needed to be replaced, which Pacific NW Solar did under warrantee. I highly recommend to anyone installing a solar system to get the wireless reporting module, as that is how I detected the panels werent producing:
One of these days I will write a routine to automate the checking of production by panel, but in the meantime I just go out periodically and verify all is performing normally. Luckily the first outage was in January when production is almost non-existent anyway, and March when I am still not in peak production. Overall maintenance continues to be manageable. I am down to cleaning the panels once a year in spring (before peak production starts), and that seems to be enough to keep them producing at optimum production.
Payback Update
My current estimated payback year for this solar system is now targeted at the end of 2024. In reading thru all the incentive information, it appears 2020 was the last year for incentives for systems installed in 2015. This will take a huge chunk out of my annual revenue. I have a balance of about $1900 bucks to pay off to break even, and without the incentives the revenue my panels produce is estimated to be just over $450 a year. One positive from a production point of view is the marginal rate on electricity has now gone over $0.11 a kilowatt, so that will help the payback. Rates have risen much slower than I projected when I installed the panels, but I do anticipate rates to continue to rise.
Usage Update
In this year of working full time at home, its not surprising that I saw a big increase in usage. Our electrical usage was up 11% for the year after 3 previous years of slowing consumption. The amount of excess solar energy our panels returned to PSE (our electric utility) was also way down, indicating much more use during the day during peak production hours. Given that this work from home thing may be a permanent way of life, I don’t anticipate usage going back down to previous levels anytime soon.
I have no changes planned for my configuration, I just hope things keep humming along. As always, if you are considering an installation and have any questions for a solar system owner, feel free to leave a comment.
For years I have been working to eliminate emotion from investing, as I believe emotion causes bad decisions to be made. Anytime I look at an investment and decide I am holding it because I ‘hope‘ it will go up – indicates to me that emotion is entering into the decision process. In past posts I have referenced my investment model that I use to make investment decisions, and that has gone a long way towards using more analytics and less emotion when making decisions, but building an investing cadence has also helped.
Before I go too much into my investing process, let me digress and mention that some of my best investments have been made not using analytics, but using more thoughtful reasoning. Probably my two best stock investments ever were Microsoft in the early 90’s, and Amazon in the late 2000’s. Both of these stocks were ridiculously overpriced at the time and the analytics I used at that time would not support those investments. But I took a ‘gut level’ flyer on those because I reasoned out the long term trajectory of these companies (which my analytics tend to ignore) and took a flyer on these companies. I am sure there are examples of where this approach has burned me (and I conveniently erased those mistakes from memory), but I do think there are times where you have to look outside of analytics.
Over the years I have built a routine that helps me unemotionally make investment decisions that I share below – reasoning without emotion is still a critical factor.
My investment model attempts to predict which stocks will outperform the market in the following month. So I purposely rigged the model to unveil the next months predictions on the 20th of every month. So starting on the 20th, I look at my holdings, and compare them to projections, and make buy sell hold decisions to make over the next 10 days. I like to have my changes settled by the first of the month, so my portfolios reflect on the first of the month my plan for that month. This is important because at the start of the month I programmatically take a snapshot of my portfolios for performance measurement purposes. I try to limit my trades between the 1st and the 20th so that I can easily measure my performance metrics.
I think it is a positive to get away from trading for 20 days each month. I typically spend time during those periods researching investments, or making improvements to my investment model, or doing more creative thinking on investing in the future.
I have to admit though, I don’t get away from portfolio management completely during this time. Typically on the weekend, I will spend some time looking over my portfolio and filling in partial positions or trimming positions that might be too big. I try not to ever add new stock positions or sell out of positions during this time, I should always do that between the 20th and the 1st. But the nice thing about making some buy/sell decisions on the weekend is the market is closed. So on Monday morning, I can revisit those weekend decisions, and see if I Monday morning me agrees with weekend me.
I am fully aware more financial planners say it would be better to spend less time looking at your investments, and just buy and hold and let them grow organically. I would also recommend that for most investors; just buy low cost mutual funds and look a them quarterly/yearly. But for me, I can sleep better at night fully understanding my investments, and being fully accountable for my investment performance. If I find my approach underperforms my mutual fund benchmarks, I think I would throw in the towel and find something else to occupy my time. But if you are like me, and want to manage your investments, give some though to a routine that helps drive analytical decision making, and make sure you measure your performance.
Previously I posted a note on Blazor authentication and how my approach worked great. As it turns out, I think that approach was wrong and it left me at a deadend. So I thought it would be worth going deeper into what I am trying to do, and how I think my new approach will work better.
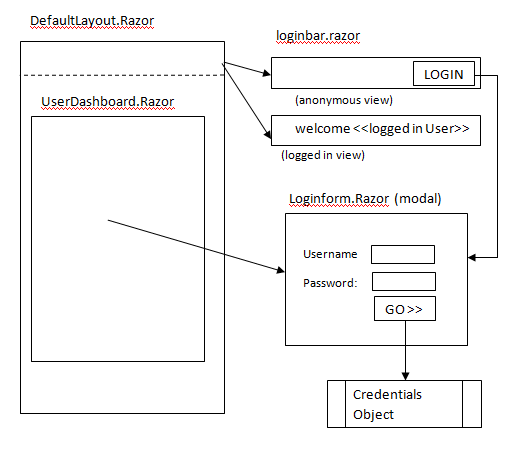
When I first design the layout and pattern for my Blazor application, I thought it was pretty straightforward. I wanted a login status bar at the top of the page showing the current logged in user, or if no usr is logged in a login button. I put my loginbar control directly in the main layout page to keep all my other pages from having to deal with it.
The problem occurred when I built a user dashboard page that I wanted to function where when that page is requested, and no one is logged in, it pops open a modal form (using Blazored Modal) and prompts the user to login. After messing with it a bit, I could get the user dashboard page to refresh after login, but could not get the login bar to update when the user logs in via this method.
After much googling and tinkering, I finally decided to deal with creating custom events to notify the controls of a login. I had been avoiding this – after working with javascript events I swore off dealing with that level of complexity on the front end. But after reading the docs, it appeared that this will be a useful tool for any Blazor project. I was really getting stymied until I stumbled upon Jason Watmore’s example on Github. That is a nice simple example of communicating between components.
I was able to adapt the example to my scenario, and it turns out to be a nice simple solution. Here is how it works. I created a ‘OnLoginComplete’ event which my login form fires when there is a successful login. I added a listener for this event to the loginbar and my userdashboard page, so when the event is fired these components wake up and refresh themselves, and reflect the username and other data important to the logged in user. Once I got the hang of it, it was quite simple.
I thought about creating an ‘OnLogout’ event, but it turns out I don’t need it. For now the only place I have a logout button is in the loginbar at the top of the page, and when that is clicked I destroy the credentials and redirect back to the home page.
After many attempts I feel like I have the right solution, and I think firing and listening for events will be handy for future projects. I took a lot of wrong turns in arriving at this solution.. but then isn’t that part of the fun of learning new languages?
I just completed an analysis of Zillow and Redfin, two companies that are competing to disrupt the real estate space. Valuing these companies presents a challenge, because neither currently are consistently profitable and are bloating their balance sheets with housing inventory. So I looked at visitor stats, which did provide an interesting way to compare the value of these companies. Both companies sell at a very high premium to the market, but I do believe long term both companies could be in interesting investment.
I have been building prediction modeling applications for years as a investor, as a way to try to identify when the various asset classes or particular stocks may be over or under priced. My current model is over 15 years old, and as you might guess is becoming a huge mess of code-spaghetti which is becoming difficult to modify.
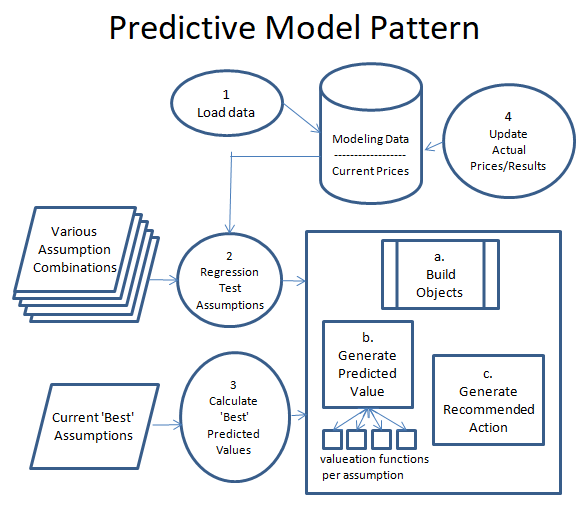
Recently, I stumbled across a full suite of college football data, and started to wonder if one could build a model to predict college football games. Rather than try to copy my existing investment model, I decided to mentally start from scratch and figure out the best way to design predictive models for maintainability. I now have a college football game prediction model up and running, using my new pattern I designed during this process:
Now this might be Data Science 101 to a data scientist, but this is not my area of expertise. My software suite is a SQL Server database and C#, tools I am very comfortable with. Rather than learn new tools and software specially built for data modeling, I thought it would be more interesting to design my own custom approach. I am a software developer, so my thinking how how to build this process was inspired my Model/View/Controller (MVC), a software design pattern that focuses on separation of logic for interconnected systems. So taking this foundation, I have broken the process of setting up an managing the model into 4 main components.
Create Program to Load Data. Before I build a model, I have to make sure I have access to the data necessary to power it. There are plenty of great API’s to gather investment data, and if necessary data can be gathered via data scraping. I have a good library of tools to call APIs, and a nice suite of data scraping tools. So building the logic usually takes some time, but the logic to gather the data can be nicely compartmentalized for easy maintenance.
Create Program to Regression Test Various Assumptions. Before building the program, you have to define a rough set of assumptions as to the cause and effects of various factors. The set of assumptions you create can only be limited by the data you have available. For example, for my College Football prediction model one assumption I tested was that a team is more valuable after a big home game loss. The assumption is the team might be more motivated to do well following a bad home loss, and potential betters are soured on the team. So you look at the data you have, then create various assumptions you can test against the data. Once you have a set of assumptions, you create a program to fire the assumptions at your prediction engine with varying the weight of each assumption each run. Doing this you hopefully identify assumptions that have no correlation to future performance, and ones that have a strong correlation or inverse correlation to future performance. Below I have expanded on how the prediction engine is built, as it is a core piece of the program.
Create Program to calculate the ‘best’ predictions. Once you have tested various factors against your historical data, choose the factors and weightings of each factor that performed best of all the factor combinations you fired at at the prediction engine. This will be what generates the predictions, then looks at the current price (or the current betting line in the case of my college football model), and determine the ‘best’ value prediction. Note that I plan to rerun my regression tests on this model quarterly, so that I can see how well the assumption weightings are holding up. If some start to deteriorate, I may adjust factors and weightings as appropriate.
Create Program to track predictions and update results. I think this is perhaps the most important piece. The prediction engine bases it’s prediction based on past data, so it is important to see if past data accurately predicts future results. So for example for the college football predictions, every Monday I run a job that updates the weekend scores, then compares the results to my predictions for the week. Each week I will look closer at the losses, to see what I missed, and maybe give me some ideas for additional factors to add. Of course, new factors may mean collecting more data, which further adds to the effort of building and maintaining the model. It is a very iterative process, as optimizations can always be made.
The Prediction Engine
Building the prediction engine is an iterative process in itself. The plan is to start small, then slowly add additional calculations over time. As long as additions are managed in an organized manner, the code base should be maintainable even after adding a large number of factors. The prediction engine (described in the big square in the diagram above) consists of 3 major parts.
a. Build Objects. The first thing to do when firing up the prediction engine is to pull the data stored in the database into a view model that exposes the data in a way to be easily accessible. These are typically complex objects that represent the entity you are making a prediction on (i.e. football game, a stock market security, asset class, etc.). For instance, a college football model would pull in a game object, which would have two teams attached to it with all the statistics and history needed for each team. For instance, a ‘bad previous week home team loss factor’ will require looking at past game performance in order to see if the a team had a bad loss in the previous week. As long as the data is there, that is a fairly simple subroutine to write.
b. Generate Predicted Value. Now that you have your data accessible – fire your list of assumption factors and weightings to calculate a value. To simplify the architecture of this, I have a separate subroutine for each factor calculation to try to avoid my logic bloat. This will allow me to isolate factors, and add new ones or delete invalid ones as necessary.
c. Generate Recommended action. Once you have calculated the value of all your assumptions against an object, you should have a score for that object. That score can then be compared to the price of the object to see if there is any action to be taken. For example, take a college football game, and given your assumptions and the data available step b came up with a calculation that the home team should win by 3 points. If the betting line has the home team favored by 14, and your threshold for action is a 7 point differential, then the recommendation action would be to place a bet on the visiting team. The same works for a stock market security. If step b calculates a stock price of $15, and the stock is priced at $10 the recommended action might be to buy the stock.
Note that it is also valuable to track the variability of the model in the form of standard deviation or R value. Some models may show a coorelation, but have a wide deviation. These deviations will help you set your ‘time to take action’ price. Typically the wider the deviation, the higher I set my action price.
Breaking the logic for this prediction engine into segmented parts should really help the management of the logic. In addition, I have a pretty good library of reusable logic components that I should be able to apply across multiple predictive models. My goal here is to slowly increase the size and scope of the calculations, while keeping the overall system pretty simple.
Now that I have my college football predictive model working, I will just continue to add assumptions to see if I can continue to increase the accuracy of my predictions. Then I will start tearing out components of my existing investment prediction engine, and rebuild it using this new model.
When will I be done with this project? Hopefully never. If all goes well, these models should be continually evolving and growing as more data is collected, and hopefully become more accurate.